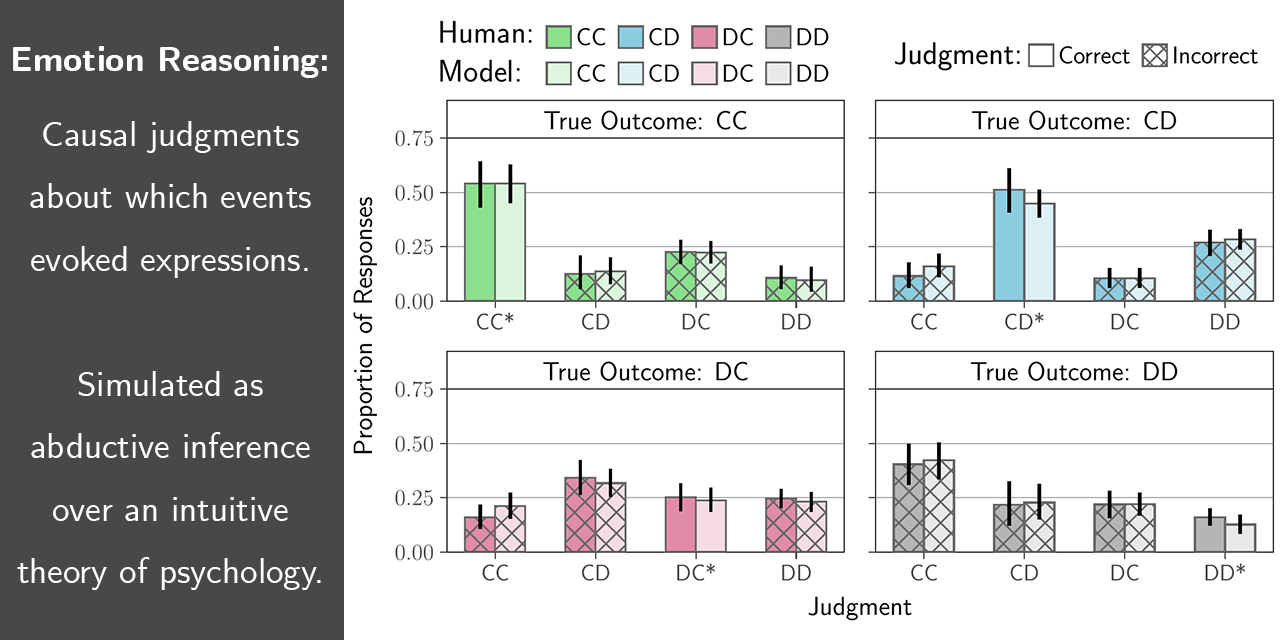
Reasoning about the antecedents of emotions:
Bayesian causal inference over an intuitive theory of mind
. . .All of the raw behavioral data, analyses, and models related to this submission are available on the github repository:
https://github.com/daeh/emotionreasoning-cogsci22.
. . .
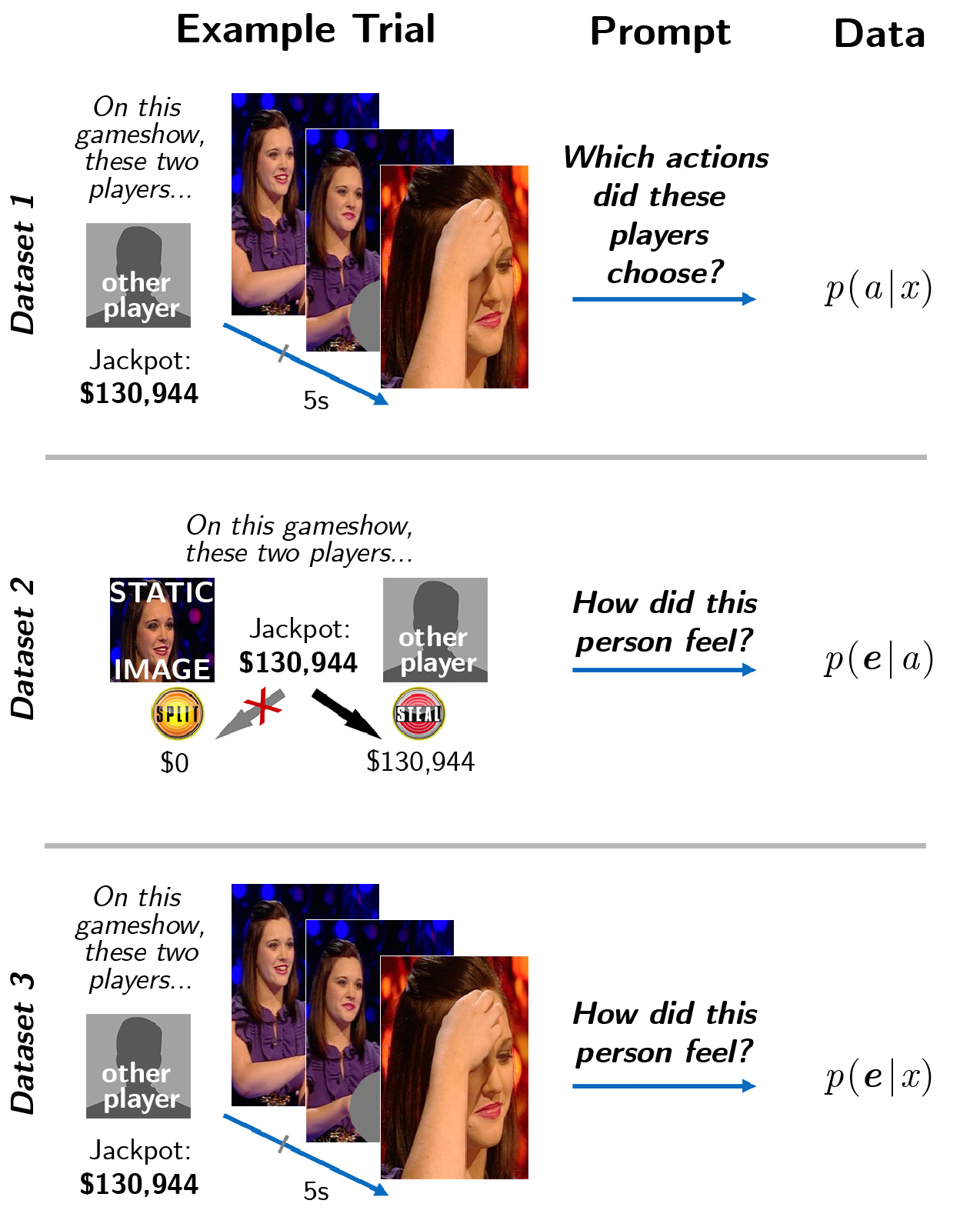
We artificially separated the perceptual information from context information in recordings of a televised British gameshow called Golden Balls. Every episode of Golden Balls culminates with two contestants playing a dramatic one-shot instantiation of the Prisoner's Dilemma. Each player is given a choice to "Split" or "Steal" a jackpot (in standard Prisoner's Dilemma notation, to "Cooperate" or "Defect", respectively). If both decide to Cooperate, they each receive half of the jackpot. If one player instead chooses Defect, that player wins the entire jackpot and the other player who chose Cooperate leaves with nothing. If both players choose Defect, both get nothing. Players negotiate with each other in front of a live audience in an attempt to convince the other to make a choice that is financially disadvantageous (to Cooperate). Each player makes a decision in private, then they simultaneously reveal their choices, all while being filmed.
The game is emotionally evocative by design. When the choices are revealed, players discover whether they have won or lost real and often substantial sums of money; and whether they have successfully cooperated, successfully duped, been duped by, or failed to dupe the other player. The TV cameras capture their spontaneous unscripted dynamic expressions, including changes of posture and expression of players' faces, shoulders, upper bodies, and hands.
We generated 88 videos of players who participated in the final round of the 5th season of the Golden Balls gameshow, which aired in 2009 (footage of the show was provided by Endemol UK). Videos were 5 seconds in duration, each depicting a single player's expressions, by splicing together footage from the moments surrounding the climactic reveal. The four outcomes were represented equally in the stimuli (N=22 for each outcome), reflecting the true distribution of play---across all 287 broadcast episodes, players were 53% likely to Cooperate, and the decisions of a player dyad (the two opposing players in the game) were statistically independent of each other. Each video silently showed a single person anticipating and reacting to a game outcome, but overt cues as to the players' decisions and the outcome of the game were masked.